
There are moments when the patterns used for querying the models of an application are far different from those used for managing its life cycle. The CQRS pattern talks about that, how to separate your changes to the model from different query access. We will go over an example in this post on when this happens and a couple of alternatives to how to improve your system scale in such a situation.
Background
You manage a system that is responsible for managing blog posts, a Content Management System (CMS). This system has two main functionalities, it allows writers to create and manage content, CRUD, and also allows readers to consume the final content. You can assume that once the Article is published it will be consumed by a high amount of readers.
Problem
Starting from using a simple model, where a SQL database is used and the same tables are shared between the writer and reader use cases, which over time becomes a bottleneck. One functionality impacts the other in terms of performance and implementing new features becomes harder due to the many different scenarios that need to be taken into consideration.
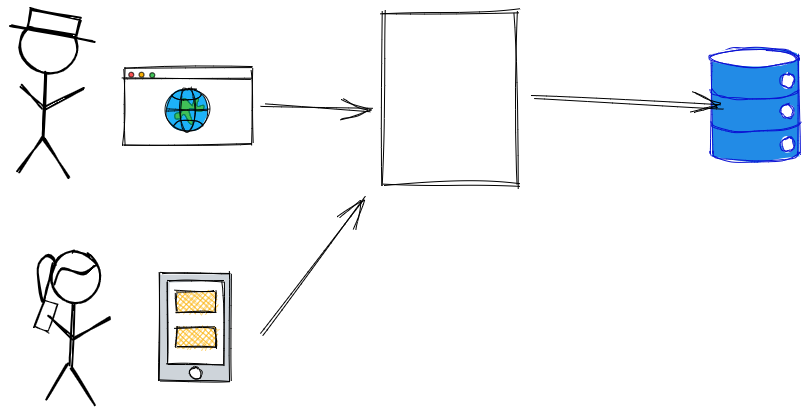
Identifying the access patterns
The first thing you should do is to identify the different access patterns that we have represented in the application. In this particular example maybe could be easy to spot them, let’s assume some use cases like:
- Reader:
- might want to use textual search to find the posts
- might want to have them pre-rendered on the backend instead of sending JSON to the front end to improve customer experience
- reference to custom tags
- Writer:
- might want to be able to store draft versions of the posts
- might want to schedule a publish time
So mapping back to the Command Query Responsibility Segregation, now we say that:
- The command is the part of the system responsible for
modifying the data(source of truth), in this case, the Writer use cases. - The query is the part of the system responsible for
retrieving the data(multiple views), in this case, the Reader use cases.
There are scientific ways of find these called
bounded contexts, you could use for instance anEvent Stormingsession. This is not the focus of the post, so let’s just assume we have this clear division. Yes, I’m talking aboutDDD, and often that is a good approach when you are growing the application. There are more links on the references.
Using the same Service
Once you’ve identified the clear division of your application, then you need to refactor the model in order to isolate them. That really means not sharing classes, tables, and resources.
We need to isolate the query from the command so we can later freely change the underlying technology or optimize it as we wish.
Before, our Article could look like the following:
1
2
3
4
5
6
7
Article {
id: UUID,
title: String,
content: String,
theme: UUID,
author: UUID
}
Since we have a relational database, you can assume that data is normalized, which means many foreign keys going around and consistency being preserved because that’s what is important when we are managing the command.
After the segregation, we could get to the scene as we have in the image below:
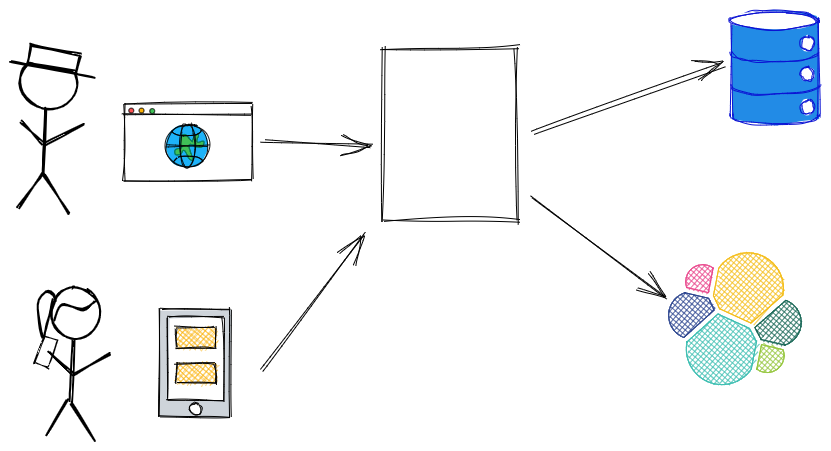
Then, new entities can be created and extracted from the original model, now optimized for the reading patterns, the Article model could look like the following (the original model is kept intact):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CompiledArticle {
id: UUID
name: String,
authorName: String,
content: String,
theme: {
...
},
tags: [
{
name: String
}
]
}
With this approach, you gain a lot of flexibility in changing the query patterns without interfering with the command patterns.
By having two data stores, you can run into the dual write problem where you need to coordinate the consistency among them. In this particular case, it shouldn’t be much of a problem and a cron job should be enough to fix the issue I’ve talked more in-depth about this problem here. Needless to say, you don’t need to have two different data stores, I’m just illustrating that you could have.
Yes, it is still a Monolithic approach, and you can still face an issue when a bug on the writer side can bring down the readers’ application, but depending on the size of your customer base, it might be a good cost/benefit. Let’s explore a more robust and expensive approach next.
Event sourcing
Event sourcing is a great way to implement CQRS, by publishing the events with the state of the entities we want to replicate, we can later use it in multiple places in completely different manners. I’ve talked about different approaches and issues you will encounter when doing this data replication in this post here: Outbox Pattern.
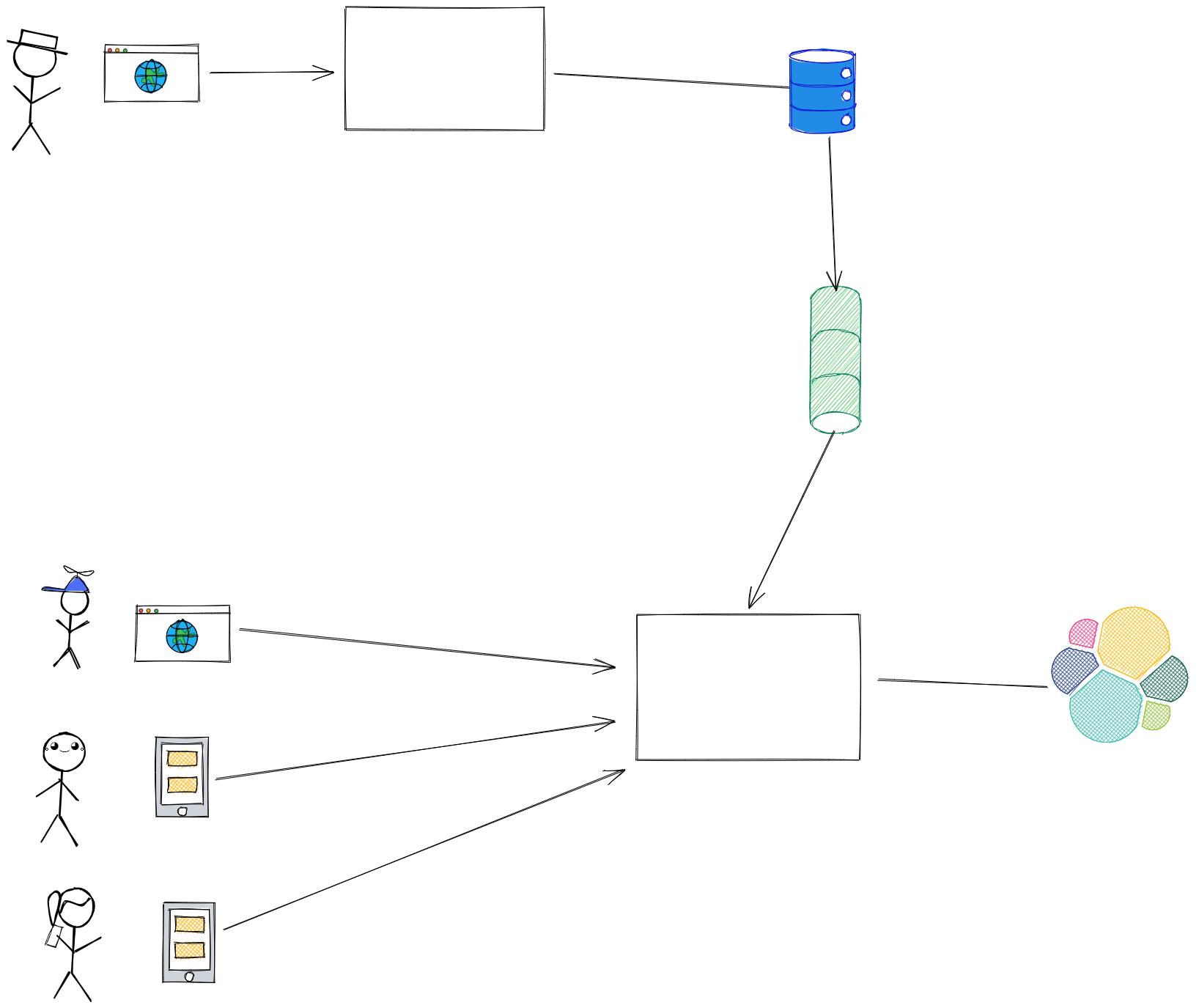
Avoid SPOF in your architecture
By using this approach, there is a clear reduction in the coupling, since the source of truth of the Article entity doesn’t know anymore who is using it and how it’s being used. Also, the single point of failure (SPOF) was removed, now if the writer part of the application is down, readers will not notice it, and the other way around as well. Depending on how we implement the topic, let’s say if we use a compacted Kafka topic, we can always bring new applications to life and have the whole replication of the database available to them.
A very important aspect of this approach is that now that we completely separated the concerns, we can have independent teams working on the different bounded contexts, without the need to interact constantly with each other. This is often neglected as an advantage, but IMHO, when a company is looking to scale productivity and paralyze work streams, this is the way to go.
There ain’t no such thing as a free lunch
This is all wonderful, but what is the catch? This approach comes with a cost, first a monetary cost of the infrastructure of course. You need a robust structure of a Kafka cluster with replication and so forth to ensure not losing events, more development on both sides, extra services, and extra CI/CD concerns, evolution of the model will be more complex as it will need to be backward compatible, etc.
There is also the cost of the eventual consistency, which your system might not be able to pay. Eventual consistency in short means, that your system might be in an inconsistent state for some time until it gets to a consistent state, after a writer changes an Article, readers will still read an old article for some time until the data is propagated. This is something that you have to accept when working with events, and I even dare to say it when working with most distributed systems.
So after all these considerations, would I say it is worth it to implement this approach? That would depend on you your scale, but it definitely is a very powerful tool and can scale your system significantly.
Conclusion
CQRS is a technique to segregate the commands from the query. It can be implemented in many different ways, but the main idea is that you can freely evolve your use cases and optimize them independently. How you would implement it, will considerably depend on the volume of requests your application handles, but it is definitely a very powerful tool to scale your application.
What do you think? Is it something that would help your application to scale? Let me know!